
Bubble in grid areas for IDs, addresses, and the like, can occupy a lot of space on a form. They also can take a lot of time for your respondents to fill in, and, depending on your audience, may be confusing to complete.
Most word processing programs allow the ability to merge textual information onto forms. If you already have the information available, why not merge and print it directly onto your forms and let Remark read and include it in your data using OCR or Optical Character Recognition.
OCR regions are used to read machine printed text on forms. These regions can be use to read numbers, letters and symbols. The regions can read single or multiple words and single or multiple lines of text. Additionally, the regions can be set to recognize limited character sets (i.e., if the area only contains numbers such as a 5-digit zip code). You can also set the language of the characters in the region (22 languages to choose from).
Any form used with Remark must follow our form design guidelines. In addition, there are some best practices for the machine generated text that should be followed:
Keep in mind that any OCR data Remark reads must fall in the same location on each form. The merged area of your form should be large enough to accommodate the longest expected text item in the area without shifting anything else on the forms. When creating the OCR regions in your Remark template, be sure to make the OCR region large enough to accommodate the longest expected merged text. If the region is not large enough, text may fall outside the region boundaries and not be included in your collected data.
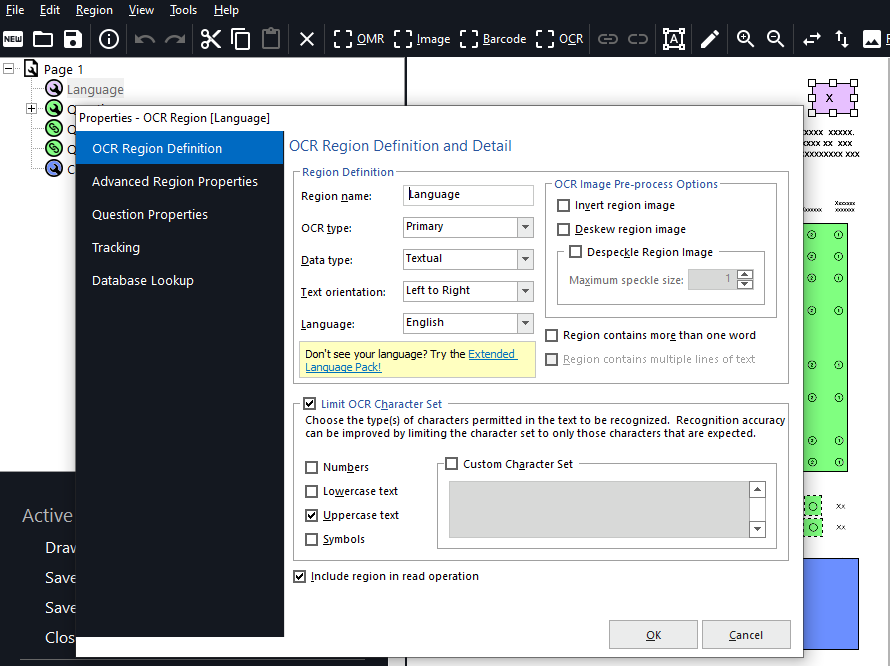
Note: OCR does not include handwriting recognition (commonly called ICR or intelligent character recognition). In order to use the OCR feature, the text must be machine or computer generated.
If you need additional information or assistance with OCR regions, please contact support at 610-647-8595 or via email at [email protected].
Share This
What Now?




